



Recently the word “ML” is in great buzz.. in tech world. Then the point now comes that should I learn ML or not. Basically, Learning is a universal skill/trait that is acquired by any living organism on this planet. Learning is defined by: the acquisition of knowledge or skills through experience, study, or by being taught.Whether that be a plant learning how to respond to light and temperature, a monkey learning how to peel a banana, or us humans learning how to ride a bike. This commonality is what makes us unique and evolve over time.
But what if I say, “Machines can learn too”
We’re in the age where machines are no different. We can teach machines how to learn and some machines can even learn on its own. This is magical phenomenon Known to be Machine Learning.
Targeted Audience: Beginners and/or Machine Learning Fresh Bloods.
Terms frequently used in this post:
Labeled data: Data consisting of a set of training examples, where each example is a pair consisting of an input and a desired output value (also called the supervisory signal, labels, etc)
Unlabeled data: It is a designation for pieces of data that have not been tagged with labels identifying characteristics, properties or classifications.
Classification: The goal is to predict discrete values, e.g. {1,0}, {True, False}, {spam, not spam}.
Regression: The goal is to predict continuous values, e.g. home prices.
Production: In simple terms, production is basically the server where the code is going to run. Incremental learning: It is a machine learning paradigm where the learning process takes place whenever new examples emerge and adjusts what has been learned according to the new examples.
Machine Learning
Machine Learning(ML) is a field of computer science that uses statistical techniques to give computer systems the ability to learn with data, without being explicitly programmed.
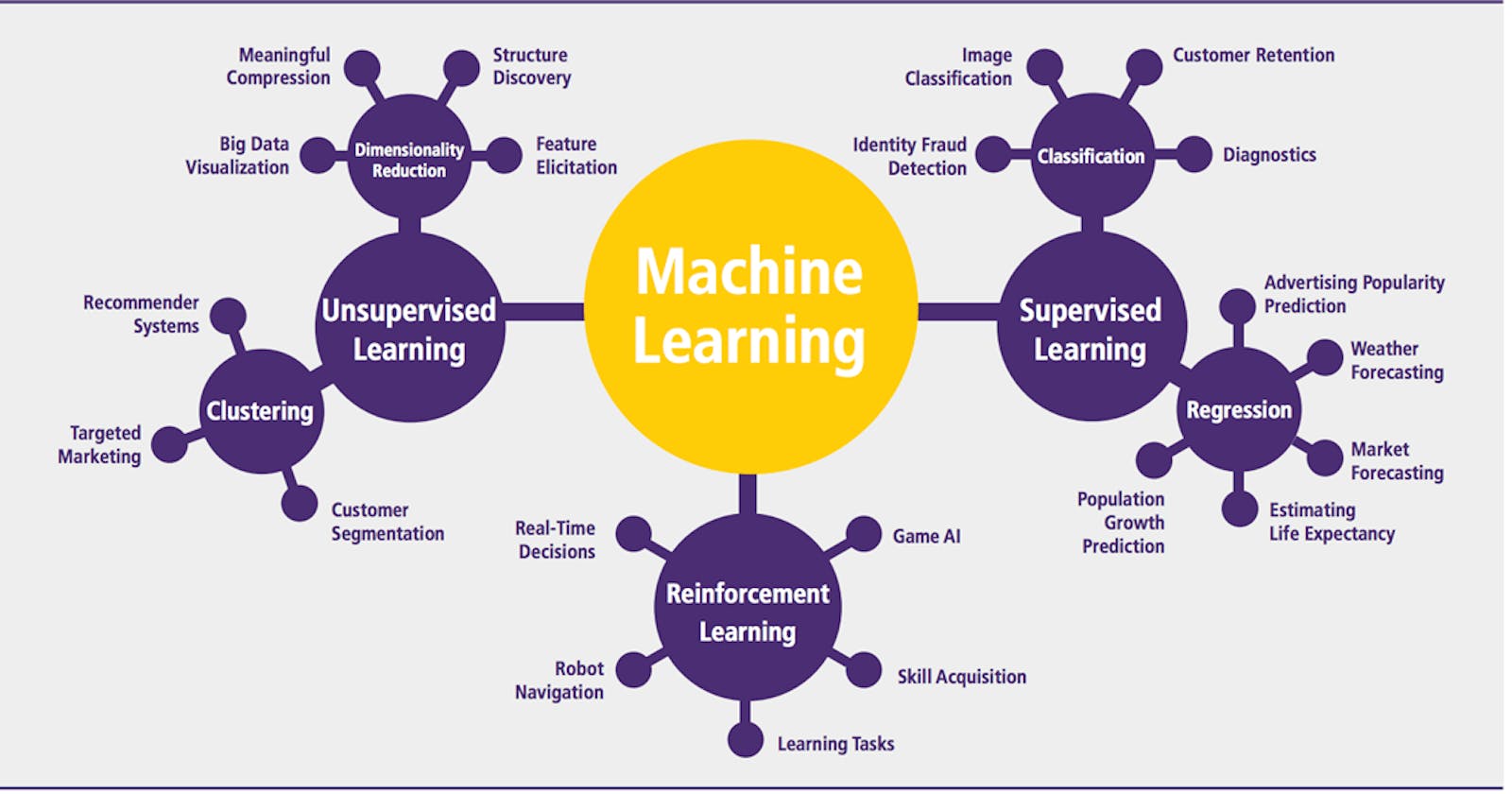
Types of Machine Learning algorithms Based on the methods and way of learning, machine learning is divided into mainly four types, which are:
- Supervised Learning: Machine learns from the labelled data.
- Unsupervised Learning: Machine learns from the unlabelled data. Meaning, there is no “right” answer given to the machine to learn, but the machine must hopefully find patterns from the data to come up with an answer.
- Semi-supervised Learning: Machine learns from the mix of labelled and unlabelled data.
- Reinforcement Learning: The machine learns through a reward-based system.
Supervised Machine Learning
Supervised learning algorithms try to model relationships and dependencies between the target prediction output and the input features such that we can predict the output values for new data based on those relationships which it learned from the previous data sets.
Depending on what you want to predict, supervised learning can used to solve two types of problems: regression or classification.
i. Regression Problem: If you want to predict continuous values, such as trying to predict the cost of a house or the weather outside in degrees, you would use regression. This type of problem doesn’t have a specific value constraint because the value could be any number with no limits.
ii. Classification Problem: If you’re interested in a problem like: “Am I ugly?” then this is a classification problem because you’re trying to classify the answer into two specific categories: yes or no (in this case the answer is yes to the question above). This is also called a, binary classification problem.
Unsupervised Machine Learning
Unsupervised learning is a type of machine learning in which models are trained using unlabelled dataset and are allowed to act on that data without any supervision.
Depending on what you want to group together, unsupervised learning can group data together by: clustering , dimensionality reduction, anomaly detection, association rule based learning.
Clustering Problem:
Unsupervised learning tries to solve this problem by looking for similarities in the data. If there is a common cluster or group, the algorithm would then categorize them in a certain form. The best of this algorithm is that it can even categorize data in n-dimension which are not visible by naked eyes. An example of this could be trying to group customers based on past buying behaviour.
Dimensionality Reduction:
Dimensionality reduction refers to techniques that reduce the number of input variables in a dataset.More input features often make a predictive modeling task more challenging to model, more generally referred to as the curse of dimensionality.
Examples: Suppose consider we have to predict the house prices. In this dataset there is a lot of columns like no. of rooms and no. of washrooms then such related columns are reduced to sqft. of house. This can be referred as feature extraction.
Anomaly Detection:
Anomaly detection is the identification of rare events, items, or observations which are suspicious because they differ significantly from standard behaviours or patterns.An example of this could be if large sums of money are spent one after another within one day and it is not your typical behaviour, a bank can block your card.
Association Problem:
Unsupervised learning tries to solve this problem by trying to understand the rules and meaning behind different groups. Finding a relationship between customer purchases is a common example of an association problem. Stores may want to know what type of products were purchased together and could possibly use this information to organize the placement of these products for easier access. One store found out that there was a strong association between customers buying beer and diapers. They deduced from this statement that males who had went out to buy diapers for their babies also tend to buy beer as well.
Semi-supervised Learning
In the previous two types, either there are no labels for all the observation in the dataset or labels are present for all the observations. Semi-supervised learning falls in between these two. In many practical situations, the cost to label is quite high, since it requires skilled human experts to do that. So, in the absence of labels in the majority of the observations but present in few, semi-supervised algorithms are the best candidates for the model building. These methods exploit the idea that even though the group memberships of the unlabelled data are unknown, this data carries important information about the group parameters. An example of this could be google photos. Google photos automatically group person’s with same face in a group and if we label any name on it then the label goes same on all of them.
Reinforcement Machine Learning
This type of machine learning requires the use of a reward/penalty system. The goal is to reward the machine when it learns correctly and to penalize the machine when it learns incorrectly.
Reinforcement Machine Learning is a subset of Artificial Intelligence. With the wide range of possible answers from the data, the process of this type of learning is an iterative step. It continuously learns.
Examples of Reinforcement Learning:
- Training a machine to learn how to play (Chess, Go)
- Training a machine how to learn and play Super Mario by itself
- Self-driving cars
Based on learning, we categorize ML into two types:
i. Instant based learning
ii. Model based learning
Instant based learning:
- The idea of the model-based approach to machine learning is to create a very broad range of models, along with suitable learning algorithms, in which many traditional machine learning techniques appear as special cases.
- It sometimes referred as lazy learning methods because they delay processing until a new instance must be classified.
- A key advantage of lazy learning is that instead of estimating the target function once for the entire instance space, these methods can estimate it locally and differently for each new instance to be classified. Eg: k-Nearest Neighbour Learning
Model based learning:
In model-based learning, the model would create a prediction line or prediction sections based on the different attributes of the data it trained on. A new data point would then fall along this line or within certain sections based on the attributes it possesses. Eg: Bayesian inference
Let’s understand more about it with the help of story.
Story
In the middle of a small town, there was a popular clothing store that was run by a mother and her daughter. The mother needed to know approximately how much money a customer was about to spend in her store because she was someone who hated surprises. The daughter studied computer science at the local college, and she decided to build a system so her mother would not need to deal with the stress of the unknown spending habits of a customer. This system would look at the characteristics of a customer as they were pulling up to the store. Some of the characteristics included the type of car the customer drove and how high-end the clothes they had on were. It was common courtesy in this town to always reflect your spending habits through your car and clothes.

A regular customer at the store was a young man named Shane. Shane was a successful businessman and one of the wealthiest members of the town. He drove a Tesla and constantly flaunted his outfits from Nordstrom. The model that the daughter had built would take new customers who also had high-end cars and expensive clothes and predict that they would spend the same amount in the store that Shane does. For the most part, this worked quite well as every rich person in this small town had about the same amount of money.
Then one day a big-time producer from Hollywood named Kevin came into town. Kevin refused to be seen in anything less than the newest Lamborghini and finest custom clothes directly from a boutique in Italy. As Kevin approached the store the model predicted that he would spend the same amount as Shane. Even though Kevin’s car and clothes were significantly more expensive than Shane’s, that was the closest data point the system had to reference. Kevin ended up spending much more money in the store than Shane ever had.
The mother was distraught over this occurrence and it allowed the daughter to rethink her model. She landed on the idea of using a system that utilized model-based learning instead of the system she had in place that used instance-based learning. That way if a new customer comes in, without attributes that closely reflect the data her model already memorized, the predictions would be more likely to reflect the amount they spend in the store.
The next time an unfamiliar car pulled up with a customer sporting unfamiliar clothing it made an accurate prediction on how much they would spend in the store. The mother was then able to sleep soundly having confidence she’d never be thrown for a loop like the time when Kevin visited the store again.
Based on training at production, ML can be categorize into two types:
i. Batch(Offline) Learning
ii. Online Learning
Batch(Offline) Learning:
- Batch learning is basically the conventional way of training machine learning model where we use the entire data to train machine learning model. There is no incremental training.
- It is mostly done offline by data scientists.
Disadvantages of batch learning
- Re-training model time and again:
- We have to update the model periodically otherwise it might not compete in real world.
Lots of data:- Suppose we create a social network or other platforms that went viral then there is a huge data, then there might be possibility that your existing hardware might not able to process such a huge data. If the data is converted to big data then we are unable to provide all the data at once. As a result, the model didn't predict or provide better result.
Hardware Limitation:- Suppose our ML model is working on the area where there is no facility of instant connectivity, we cannot do something like to fetch the data & re-train the model. We don't have such facility.
Let's consider scenarios:
scenario 1:- Suppose military is using our model to track missile or enemies where there is no proper internet facility, then at that moment we cannot fetch our model and re-train it. We can only track & re-train it when they came to area where there is proper internet facility.
scenario 2:- Suppose we have used the our machine learning model in software which is integrated in satellite and sent in outer space, then we cannot update our model.
So these are the few scenarios where batch learning fails.
Availability:- Suppose the social networking site generate the newsfeed and it update itself in every 24 hrs of period and something went viral today then it will generate the newsfeed only after 24 hrs which is of no use or less relevant to the user because the user already knows about it.
Online Learning:
- Online learning quite unlike batch learning is done incrementally, in which data becomes available in a sequential order and is used to update the best predictor for future data at each step. These data is sometime referred as mini batches.
- Since we use mini batches to train the model. It can be done on server too. That's the reason we call this as online learning because the model is learning when it is online.
When to use online learning
Concept drift : When the nature of the problem is volatile, in that case we can use online learning. Eg: E-commerce platforms, Stock Exchange etc..
Cost Effective : When working on larger scale, online learning saves cost than batch learning. Because we work on mini batches in online learning.
Faster Solution : Online learning is really fast because it works on mini batches and provide accurate result too.
Disadvantages of online learning
- Risky : efficient tools are not out there for now.
- Tricky to use

Final Notes
This is my first article on machine learning and I hope you have learned something! If there is anything that you guys would like to add to this article, feel free to leave a message and don’t hesitate!
Any sort of feedback is truly appreciated. Don’t be afraid to share this! Thanks!
Let me know what you think about this, if you have suggestion of a topic you would love to see here get in touch.
Last Thing
If you enjoyed the writings show some love to it & recommend this article so that others can see it.